|
| ||
|
| ||
|


|
Supported & Funded by E-Learning Division Department of Information Technology Ministry of Communications & Information Technology Government of India |
|
| ||
|
| ||
|
|
Supported & Funded by E-Learning Division Department of Information Technology Ministry of Communications & Information Technology Government of India |
|
Technical Background and Need for Data Compression Reliable and fast delivery of data over existing communication channel along with storages of data is important to modern information driven society. The major communication channel includes World Wide Web (public domain), telephonic conferencing, video conferencing (public and dedicated domain), and movable storage media etc. Rapid growth in the domain of computer, communication and entertainment; another problem of heterogeneous network (in the terms of channel bandwidth, receiver capacity etc.) come into the picture. These problems force us to explore the new methodologies for compression that must include the ways to handle the diversity of communication channels (in terms of different bandwidth); and it should be fast and reliable. The direct impact of data compression can be seen on e-learning systems, where the students might be separated from tutor either in time or space or both. Actually, this is the criterion that classifies systems supporting e-learning in two discrete kinds:
In a synchronous e-learning system the tutor is separated from the students in space. Typical synchronous delivery systems are video conferencing systems, audio conferences and the telephone. On the other hand, in asynchronous e-learning systems, the tutor is separated from the students either in time or both in time and space. The students view stored educational material, with obvious limitations as far as interaction between students and tutor is concerned. Typical delivery systems of this type are websites, audio/video cassettes, postal mail and CD-ROM’s. Both types of systems are being used in higher education; because of vast amount of data is generated during full lecture exercise and it is highly desired in both way that the amount of data is reduced which further reduce the storage space required (in asynchronous mode) as well as less bandwidth requirement (for synchronous mode). However, the asynchronous type of system has received more attention in the past few years, with the obvious result that systems supporting synchronous e-learning are lagging behind because several greater constraints such as requirement of more bandwidth, nearly healthy communication link. Therefore, there is an urgent need to put more effort on data compression which also reduces the burden on communication link to facilitate the student-teacher interaction in synchronous mode as this lacks in asynchronous mode. Our goal is to develop a set of algorithms based on different techniques, to compress image/video along with audio data, for both synchronous and asynchronous modes with multiple encoding techniques including linear transformations and its applications to wireless networks for robust and uninterrupted e-learning.
(A.2) Theoretical Background of Data Compression When the general term of data is used here, main source of this data is image (gray or color), audio, video or both audio and video. Video is made of different frames (same as still image) passed in a sequence with 30 frames per second (fps) typically. Image, video, and audio data (signal) can be compressed due to these factors: I. There are generally three types of redundancies exist in image/video data as: 1. Spatial Redundancy or Spatial Correlation: Within the single image or single frame of video, there exists the significant correlation among the neighbor samples (pixels) and results spatial redundancy in data. 2. Spectral Redundancy or Spectral Correlation: For the data acquired from multiple sources (e.g. multiple cameras), there exists significant correlation amongst samples from these sources. This correlation is referred as spectral correlation and results the spectral redundancy in data. 3. Temporal Correlation or Temporal Redundancy: For temporal data (such as audio and video), there is significant correlation amongst samples in different segment of time. This is referred as temporal correlation and results the temporal redundancy in data. The key idea in any compression is to reduce the number of highly correlated samples to lesser representative samples, in different group of correlated samples, which in turn results in reduced redundancy across the data and hence reduced size of data. II. There is considerable information in the data that is irrelevant from a perceptual point of view and discarding this information results the reduced amount of data. III. Some data tends to have high-level features that are redundant across space and time; i.e. data is of a fractal nature.
(B) A Typical Block Diagram of E-Learning Classroom
Figure 1: A Typical Block Diagram of E-Learning Classroom
(C) General Frameworks of Coder and Decoder
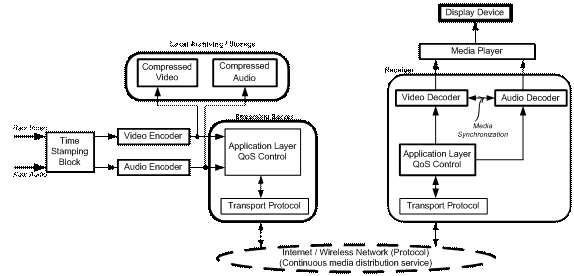
Figure 2: Full Architecture of End to End Audio / Video Distribution and Storage Network
Description I. The full end to end delivery system contains the major areas as:
II. Typical constraints encounters during development of such system as:
III. Summary of functionality of different blocks (figure 2) a. Video/Image Compression It has mainly two type of basic functionality to generate the compressed data, as :
b. Application layer QoS (Quality of Service) for streaming Video: This block is mainly responsible to cope the varying network conditions and ensures the presentation quality requested by user. It has mainly two functions, as:
c. Continuous Media Distribution Service: It is built on the top of network protocol used and designed to take support of network to reduce delay, packet loss and hence to achieve QoS and efficiency for audio, video transfer over the network. It mainly includes:
d. Streaming Server: It processes multimedia data under timing constraints and support interactive control (e.g. pause, play, fast-forward, fast backward etc.). The proper working of streaming server requires that it must receive the media components in synchronous manner (at most very small time delay). It has mainly two parts:
e. Media Synchronization Mechanism: It synchronizes the timing of audio and video streams while decoding to have faithful reconstruction at receiving side. f. Protocols for Streaming Media: It can be of three types depending upon network:
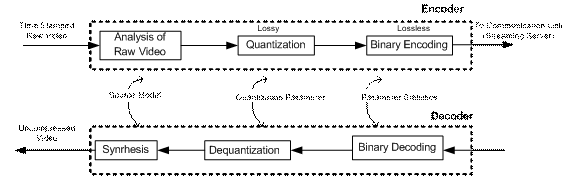
(D) General Coder Framework
Figure 3: General Framework for Implementing Encoder / Decoder for Video
I. Two Classes of Algorithms to Implement Video Coding/Decoding Systems
regions and objects in a video sequence and code those. II. Model Adapted for Coding: There are some factors for model adapting the coding, as:
III. Description of Blocks Used (figure 3) a. Source Model: Video Modeling Technique and based on parameters of source model, coder seeks to describe the content of video sequence. b. Analysis: Digitized raw video described using parameters of source model.
c. Quantization: Parameters of source model are quantized into finite set of symbols depending upon constraint on bit-rate and distortion. d. Binary Encoding: Quantized parameters are mapped to binary code words using lossless coding technique.
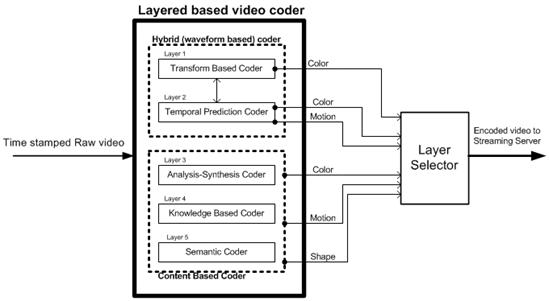
(E) General Model of Layered Video Coder
Figure 4: Block Diagram Layered Video Codec
Description of Different Layers (figure 4): Layer 1: Transmits only the color information (parameters) of statistically independent pixels (corresponds to ‘I’ frame of hybrid coder). Layer 2: Allows the additional transmission of motion parameters for the block of fixed size and position (corresponds to ‘P’ and ‘B’ frame coder of hybrid coder). Layer 3: Allows to transmission of shape information in order to describe arbitrarily shaped objects. Layer 4: The knowledge of scene contents is extracted from video sequence and transmitted in order to apply scene dependent object model. Layer 5: Transmits the high level symbols for describing complex behaviors of objects. Layer Selector: This block selects the layer depending upon the object properties, video quality needed, bit rate, coding error etc. |
||
|
|
|
|
|
|
Chief
Investigator |
|
Developed by Karmaa Lab,
Indian Institute of Technology, Kanpur,
www.iitk.ac.in/karmaa | |